Zero-Cost AI Content Pipeline: Gemma, Ollama, OpenClaw
Introduction to the Autonomous Local AI Paradigm
The architectural paradigm of artificial intelligence integration has undergone a radical transformation, pivoting from cloud-dependent, reactive chatbot interfaces toward localized, fully autonomous agentic systems. Historically, engineering a robust, end-to-end content generation pipeline necessitated the orchestration of multiple disparate Software-as-a-Service (SaaS) platforms. This legacy approach required organizations and creators to absorb exorbitant, variable per-token API costs, surrender data privacy and intellectual property to centralized inference providers, and manually stitch together brittle integrations using external automation platforms. However, the maturation of highly capable local large language models (LLMs), paired with sophisticated execution and orchestration frameworks, has completely inverted this operational model. It is now entirely feasible to architect a zero-cost, fully autonomous content generation pipeline that executes continuously on consumer-grade or dedicated local hardware.
This comprehensive report explores the precise technical architecture, system configuration, and strategic deployment required to achieve this autonomy using a specialized triad of open-source technologies: Google’s Gemma 4 models, the Ollama localized inference engine, and the OpenClaw autonomous agent framework, which was formerly and still colloquially known within developer ecosystems as Moltbot or Clawdbot.
The convergence of these three specific tools represents a profound second-order shift in how digital infrastructure is conceptualized and deployed. Rather than treating artificial intelligence as a remote service to be queried synchronously, the Gemma-Ollama-OpenClaw stack positions the AI as a localized operating system daemon—a persistent digital employee. Within this architecture, the agent possesses persistent temporal memory, system-level file access, and temporal awareness facilitated by advanced scheduling mechanisms. Consequently, the economic model of content generation transitions from a variable marginal cost structure—where every generated word incurs a financial penalty—to a strictly fixed-cost model bounded only by the depreciation lifecycle of the local hardware and standard electricity costs. This localized approach not only mathematically eliminates API billing but also ensures that proprietary training data, unreleased drafts, brand guidelines, and strategic content roadmaps remain hermetically sealed within the host machine, satisfying stringent enterprise compliance and data sovereignty requirements.
Furthermore, the strategic utility of this pipeline extends far beyond mere text completion or summary generation. By integrating OpenClaw’s extensive tool-calling capabilities with Gemma 4’s refined reasoning architecture, the system is empowered to autonomously research esoteric topics, scrape real-time web data, generate multi-stage drafts, optimize the output for specific platform algorithms, and distribute the final content across social networks or content management systems. The subsequent sections of this report will meticulously deconstruct each granular layer of this architecture. The analysis will detail the hardware prerequisites necessary for stable inference, the specific daemon configurations required for optimal performance, the complex memory management systems vital for long-term narrative consistency, and the advanced agentic workflows required to deploy a production-grade, zero-cost content generation pipeline capable of operating without human intervention.

Local Inference Infrastructure: Google Gemma 4 via Ollama
Hardware Constraints and the Gemma 4 Parameter Matrix

Deploying a local large language model necessitates a rigorous, empirical assessment of hardware capabilities, specifically regarding the availability of unified memory (found in Apple Silicon architectures) or the specific combination of standard Random Access Memory (RAM) and Video RAM (VRAM) in traditional PC builds. The Gemma 4 architecture is uniquely optimized to serve a diverse array of hardware ecosystems, offering a spectrum of model sizes that scale linearly with the available computational resources of the host machine. Selecting the appropriate parameter size is a critical, foundational decision that directly dictates the agent’s ability to reliably generate sophisticated content and strictly adhere to the rigid JSON schemas required for successful tool execution within the OpenClaw environment.
The entry-level variant, designated as Gemma 4 1B, is engineered primarily for edge computing devices, mobile platforms, and embedded systems, requiring a minimal footprint of approximately 4 GB of memory. While computationally efficient, its highly compressed parameter count frequently struggles with the nuanced, multi-step logical reasoning required for autonomous pipeline orchestration and complex agentic workflows. The intermediate tier, Gemma 4 4B, represents a functional operational baseline for most modern consumer workstations equipped with at least 8 GB of RAM. This model is capable of basic text generation and localized search assistance; however, empirical evidence suggests the 4B model may exhibit significant instability and hallucination when instructed to output the strict, nested JSON arrays required by OpenClaw for file manipulation or web execution.
For a highly reliable, production-grade content generation pipeline, the Gemma 4 12B model emerges as the optimal balance between performance velocity and hardware accessibility. Requiring an allocation of approximately 16 GB of system memory, this specific variant demonstrates vastly superior logical reasoning, complex multi-turn instruction following, and highly reliable tool-calling execution parameters. Workstations equipped with Apple M-series chips (which leverage high-bandwidth unified memory) or dedicated modern GPUs (such as the NVIDIA RTX 3000/4000/5000 series or AMD Radeon AI-enabled architectures) will experience significant hardware acceleration during inference. When accelerated, these localized systems can achieve token generation throughputs that frequently rival or exceed the latencies of commercial cloud APIs, processing up to 140 tokens per second on premium hardware.
For enterprise-grade, frontier-level generation quality, the Gemma 4 27B model (alongside its 26B and 31B quantization variants) demands upwards of 32 GB of system memory. This tier is best suited for dedicated local servers or high-end desktop workstations and is ideal for pipelines requiring deep, academic-level research synthesis or highly complex multi-modal content formatting.
| Gemma 4 Variant | Primary Architectural Focus | Minimum Memory Requirement (RAM+VRAM) | Optimal Hardware Deployment Profile | Pipeline Execution Suitability |
|---|---|---|---|---|
| Gemma 4 1B | Edge Computing & Mobile | 4.0 GB | Flagship Android devices, legacy hardware | Inadequate for reliable agentic tool-calling. |
| Gemma 4 4B | Lightweight Workstations | 6.0 - 8.0 GB | Standard consumer laptops | Functional for basic drafting; logic is brittle. |
| Gemma 4 12B | Mid-range Orchestration | 12.0 - 16.0 GB | M-series Macs, RTX 4060 GPUs | Optimal equilibrium; highly reliable for automation. |
| Gemma 4 27B+ | High-end Enterprise | 32.0 GB+ | Multi-GPU servers, Mac Studio | Frontier quality; ideal for deep technical synthesis. |
Quantization Mechanics and Inference Engine Optimization
Operating a 12-billion or 27-billion parameter language model in full 16-bit floating-point precision (FP16) or 32-bit precision (FP32) requires excessive memory bandwidth and capacity, rendering the deployment economically and practically prohibitive for standard consumer hardware. The Ollama inference engine successfully bypasses this fundamental hardware limitation by seamlessly leveraging advanced model quantization techniques. This mathematical process effectively compresses the neural network’s model weights into 8-bit or 4-bit representations, frequently utilizing the K-means clustering quantization standards like Q4_K_M. This mathematical approximation marginally degrades the model’s absolute theoretical accuracy in edge cases but drastically reduces its memory footprint in VRAM while simultaneously exponentially increasing the speed of inference.
When configuring the Ollama engine specifically for an autonomous content generation pipeline, executing the pull command for the standard 4-bit or 8-bit quantized version of the Gemma 4 model is highly recommended for optimal stability. The system initialization begins with the standard package installation across diverse operating system environments.
On macOS, this is achieved via direct Homebrew commands or downloading the packaged zip file; on Linux, an automated bash script provisions the engine; and on Windows, a standard executable configures the environment. Furthermore, for organizational deployments requiring massive scale without local hardware, Ollama integrates natively with serverless environments such as Google Cloud Run, allowing administrators to provision GPU instances from cold-start to active driver readiness in under five seconds, scaling infinitely based on content demand.
Once installed natively on a local machine, the Ollama daemon runs continuously as a background service, binding by default to the standard localhost port 11434. The system administrator initiates the local download and compilation of the model weights by executing the terminal command tailored to the hardware profile, such as ollama pull gemma4:12b, directly fetching the pre-quantized manifest and layers.
A critical underlying architectural insight regarding local inference pipelines involves the strategic management of the model’s context window. Content generation workflows inherently require massive context retention; the artificial intelligence must continuously hold the original system instructions, detailed brand style guides, previously generated drafts, and OpenClaw’s complex internal prompts in its active memory. By default, to preserve VRAM and prevent system crashes, local inference engines may artificially constrain the active context window. To facilitate long-form article generation or massive document analysis, the Ollama environment must be explicitly and forcefully configured to maximize context retention.
Administrators must inject system-level environment variables to modify the daemon’s behavior. Explicitly setting OLLAMA_CONTEXT_LENGTH=16384 or higher ensures the model can ingest large data sets. Furthermore, enabling modern architectural attention mechanisms by setting OLLAMA_FLASH_ATTENTION=1 is absolutely vital. Flash Attention fundamentally alters how the model calculates attention scores, reducing the quadratic memory complexity of standard transformer architectures into a more linear, manageable footprint. This prevents catastrophic system failure (Out-Of-Memory errors) when the OpenClaw agent attempts to read massive web-scraped documents or compiles lengthy, multi-chapter articles. Finally, enabling the new inference engine via OLLAMA_NEW_ENGINE=1 further optimizes routing logic and execution speeds.
Autonomous Orchestration Framework: The OpenClaw Architecture
The Core Architecture of the Gateway Service
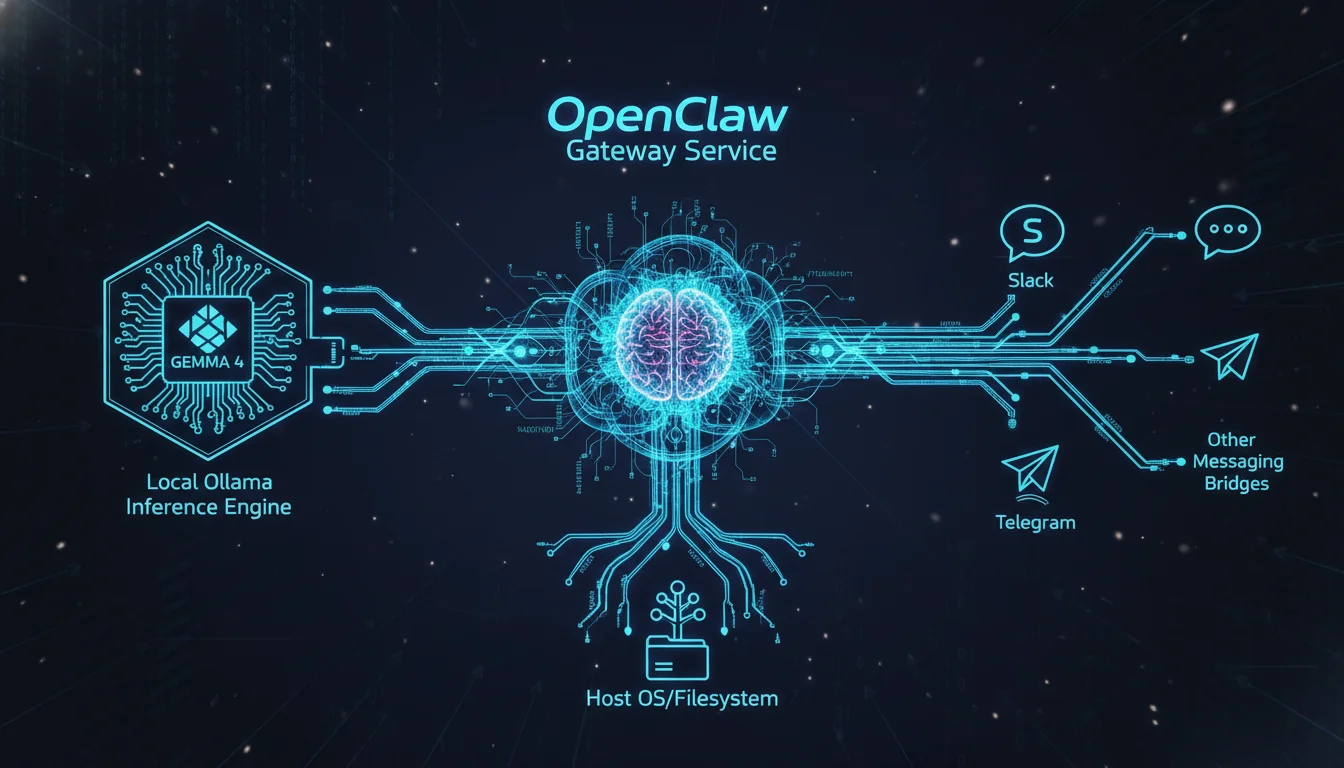
The OpenClaw architecture is fundamentally distinct from conventional, proprietary artificial intelligence interfaces like ChatGPT or Claude.ai. It entirely abandons the traditional web-browser-to-cloud-server interaction paradigm in favor of a localized Gateway Service combined with a persistent, file-based workspace on the user’s hard drive. The Gateway Service operates as a continuous background daemon (managed via systemd on Linux, launchd on macOS, or within WSL2 on Windows) that acts as the central neurological hub. This central hub manages all complex API routing, execution of temporal scheduling algorithms, and the persistence of agent state logic. The Gateway connects three distinct operational domains: the primary inference engine (Ollama serving Gemma 4), the external communication telemetry (the messaging bridges), and the host operating system’s internal filesystem and terminal.
Rather than forcing the human operator to authenticate into a dedicated, isolated web dashboard, OpenClaw integrates directly into the unified communication streams the operator already utilizes daily. Through sophisticated, real-time messaging bridges, the gateway daemon connects securely to over ten major platforms, including Slack (via Socket Mode), Telegram (via Bot API), Discord, iMessage, Signal, and WhatsApp (utilizing the Baileys protocol). This integration embeds the AI directly into professional and personal communication workflows, allowing a user to text their local desktop from a mobile device anywhere in the world to initiate a content pipeline.
However, as widely documented in practical enterprise deployments, the choice of messaging bridge significantly impacts operational security. Utilizing WhatsApp for system-level administration introduces severe systemic risks due to its architectural lack of guardrails; a WhatsApp message translates to direct command execution without robust approval workflows or auditable activity logs. A minor typographical error sent via WhatsApp could inadvertently instruct the agent to execute destructive shell commands against a database. Therefore, routing OpenClaw telemetry through Slack or Telegram is vastly preferred for professional content generation environments. Slack environments natively support conversation threads, dedicated operational channels, robust audit logging, and secure OAuth token exchanges over Socket Mode, eliminating the need to expose public webhook endpoints.
Workspace Metaphysics: The File-Based Agent Identity
The most profound, defining innovation of the OpenClaw architecture is its absolute reliance on a persistent, plain-text, file-based workspace to construct the agent’s identity, operational capabilities, and historical memory. Every interaction, instruction parameter, system prompt, and behavioral rule is stored natively as a standard Markdown (.md) file within the local ~/clawd/ directory structure. This transparent design philosophy ensures that the autonomous agent is fully hackable, easily trackable via standard version control systems (like Git), and completely auditable by human operators.
The OpenClaw runtime engine assembles its context window dynamically by injecting these specific primary files into the LLM prompt during every single evaluation loop, defining the absolute boundaries of the agent’s behavior. The fundamental system prompt is divided logically and hierarchically across these core documents.
Workspace File Designation
SOUL.md
Defines fundamental personality, ethical guardrails, and base operating principles. Dictates the default overarching tone (e.g., authoritative, conversational, or satirical) applied to all generated drafts.
AGENTS.md
Catalogs the available specialized sub-agents, personas, or distinct organizational roles. Architecturally separates the “Data Researcher” persona from the “Copy Editor” or “SEO Optimization Specialist” persona.
USER.md
Retains persistent, evolving data regarding the human operator’s context and preferences. Stores strict brand guidelines, preferred vocabulary, formatting rules, and the human’s organizational role.
TOOLS.md
Explicitly defines allowed executable actions, API schemas, and operating system permissions. Grants specific authorization to execute Python scripts, access local markdown files, trigger web scraping nodes, or utilize external publishing APIs.
MEMORY.md
Facilitates long-term context retention and chronological semantic logging. Preserves records of past topics covered to prevent content duplication and ensure long-term narrative continuity across campaigns.
HEARTBEAT.md
Defines autonomous temporal schedules and conditional polling triggers. Establishes the chron-job timing for when the agent should autonomously begin researching or drafting content without human initiation.
In addition to these foundational Markdown files, the workspace contains a canvas/ directory functioning as the agent’s active working sandbox where drafts are generated and edited, and a memory/ directory that archives persistent vector or flat-file conversation logs. Because the agent’s entire persona and functional capability are derived from these plain text files, updating the behavior of the content generation pipeline simply requires editing a text document rather than recompiling software code.
System Integration: Fusing OpenClaw with Local Ollama Inference
Deploying OpenClaw and mapping its routing logic to the localized Ollama instance requires specific network bindings and JSON configuration alignments. Because the OpenClaw framework was originally designed and optimized to interface seamlessly with premium cloud providers such as Anthropic’s Claude 3.5 Sonnet or OpenAI’s GPT-4, the system must be explicitly and carefully routed to recognize the local Ollama daemon as a valid, OpenAI-compatible REST endpoint.
Deployment, Provisioning, and Networking
The modern iteration of OpenClaw provides a highly streamlined provisioning sequence integrated directly with the Ollama command-line interface.
By executing a single initialization command within the terminal—ollama launch openclaw—the system executes a comprehensive automated setup routine. The Ollama daemon automatically detects missing system dependencies, securely installs the OpenClaw gateway daemon via the Node Package Manager (npm), and initiates a visual graphical interface for onboarding. This automated setup procedure configures the primary local model, establishes necessary user security warnings regarding the inherent risks of autonomous tool execution, and automatically binds the default web search and fetch plugin modules.
For advanced environments requiring highly customized orchestration or remote server deployments—such as executing the heavy inference workload on a dedicated Linux GPU server while the lightweight OpenClaw agent daemon resides on a separate network node or laptop—manual network configuration is strictly necessary. Administrators must alter the system daemon configuration of the Ollama host server to explicitly bind to all network interfaces (0.0.0.0) rather than strictly restricting traffic to localhost (127.0.0.1). This is typically achieved by injecting systemd environment variables, creating an override configuration file (/etc/systemd/system/ollama.service.d/override.conf) dictating Environment=”OLLAMA_HOST=0.0.0.0:11434”, and restarting the system daemon. Alternatively, the entire architecture can be provisioned within isolated Docker containers using a robust docker-compose.yml file, mapping the internal Docker networks to point the OpenClaw container’s OLLAMA_API_URL environment variable directly to the host’s Ollama port.
API Routing and Context Mapping Configurations
The core logical mapping between the orchestrator and the LLM occurs within the central OpenClaw configuration file, formatted as a structured JSON document residing natively in the user’s home directory (e.g., ~/.clawdbot/moltbot.json or openclaw.json). Within this critical configuration matrix, the default commercial inference provider must be overridden. The system administrator creates a nested providers block, explicitly defining the ollama service, setting the baseUrl to and defining the API protocol as openai-completions. Authentication headers are generally set to false or bypassed for local deployments since the traffic does not traverse the public internet, and the specific Gemma 4 model variant (e.g., gemma4:12b) is declared as the primary analytical engine.
A critical secondary configuration within this JSON structure involves context window alignment between the two distinct software systems. The OpenClaw JSON configuration file strictly dictates the maximum token payload the gateway will attempt to package and send to the model. If the OpenClaw configuration permits a massive 128,000 token payload, but the underlying Ollama instance was not initialized with a corresponding OLLAMA_CONTEXT_LENGTH variable, the pipeline will inevitably crash, truncate data, or fail silently during long-form document processing. A harmonious, explicit alignment between the configured maximum context window in the OpenClaw parameters and the environment variables of the Ollama server is paramount for architectural stability and pipeline reliability.
| JSON Configuration Node | Target Variable | Function in the Pipeline |
|---|---|---|
| models.providers.ollama.baseUrl | Directs OpenClaw traffic to the local Ollama daemon rather than Anthropic. | |
| models.providers.ollama.api | openai-completions Forces OpenClaw to format prompts using the standard OpenAI REST structure, which Ollama inherently understands. | |
| agents.defaults.model.primary | ollama/gemma4:12b Sets the specific Gemma variant as the default reasoning engine for all unassigned tasks. | |
| tools.exec.security | full Mandates security constraints on how the LLM can execute shell commands on the host machine. | |
| agents.defaults.workspace | /home/user/clawd Specifies the absolute directory path where the pipeline’s drafts, rules, and memory files reside. |
Constructing the Proactive Content Generation Pipeline
With the infrastructure stabilized, networked, and integrated, the system is technically capable but remains operationally passive. Transforming this static setup into an automated, zero-cost content generation pipeline requires engineering specific proactive workflows. This transformation involves shifting the agent from a purely reactive mode (waiting idly for human text input) to a proactive mode (operating autonomously on a defined schedule) through the implementation of temporal heartbeats and specialized execution skills.
The Paradigm of Proactive Automation: Heartbeats
The traditional interaction pattern with a large language model is purely synchronous: a human issues a prompt, the machine generates a response, and the session ends. OpenClaw shatters this limitation via its internal chron-like temporal scheduling system, controlled entirely through plain natural language instructions written within the dedicated HEARTBEAT.md file. The heartbeat mechanism is a built-in temporal loop where the gateway daemon periodically “wakes up” the agent. At a specified interval, the system fetches the system clock, reads the contents of the HEARTBEAT.md file, and constructs an invisible background prompt: “This is a scheduled heartbeat check. Review the following tasks and execute any necessary actions using available skills. If there is nothing that requires attention, respond ONLY with: HEARTBEAT_OK”.
The Gemma 4 agent then executes a cognitive reasoning loop to determine if any action is required based on the injected temporal context and external data conditions. If the heartbeat instructions dictate that industry research must be conducted every Monday morning at 09:00, the agent will independently recognize the true condition, utilize its configured web tools to scrape relevant data sources, synthesize the findings, and deliver a comprehensive briefing to the user via the connected Slack or Telegram bridge.
For a fully automated content generation pipeline, the heartbeat serves as the primary operational orchestrator. An administrator can draft explicit plain-text instructions dictating a complex daily routine. For example, the agent can be instructed to silently monitor specific RSS feeds, competitor blogs, or industry news aggregators every morning at a designated hour. It can be directed to autonomously compile a list of trending topics, cross-reference these topics against its localized MEMORY.md bank to ensure it does not repeat past articles, and automatically draft high-level outlines for the three most viable subjects. This temporal autonomy creates a self-sustaining ideation engine that operates continuously without any human initiation.
Furthermore, advanced heartbeat implementations can utilize highly efficient rotating cadences. Rather than executing a massive, token-heavy evaluation prompt every thirty minutes containing all possible pipeline tasks, the instructions can isolate tasks based on precise time windows. The system can check emails for high-priority executive directives hourly, but only execute the compute-heavy task of generating full long-form articles on specific days of the week. This strategic orchestration significantly conserves local computational resources and prevents hardware saturation.
Skill Engineering and Multi-Modal Workflows
While the temporal heartbeat dictates when the agent acts, custom skills dictate precisely how it executes complex, multi-step creative processes. A skill in the OpenClaw ecosystem is a self-contained, highly shareable module consisting of a primary SKILL.md file that encapsulates prompt engineering, tool usage sequences, procedural logic, and API references. By defining skills, users create highly reusable workflow templates that guarantee structural consistency across the entire content pipeline.
Writing a custom skill for content generation involves structuring a Markdown document containing YAML frontmatter at the top—which defines the module’s system name, description, and required dynamic parameters—followed by a plain-text markdown body containing the rigorous step-by-step instructions the Gemma 4 agent must follow at runtime. This file-based architecture is profoundly elegant because it empowers non-programmers to “code” autonomous workflows using natural language directives.
A comprehensive, multi-modal content generation pipeline typically requires engineering a suite of interrelated skills:
- The Research and Ingestion Protocol: A skill engineered to accept a raw topic parameter, autonomously utilize web-scraping tool nodes to gather primary source material, extract relevant statistical data, bypass basic anti-bot protections, and compile a structured markdown briefing document saved to the canvas/ directory.
- The Advanced Drafting Engine: A skill that ingests the prior research briefing and utilizes the Gemma 4 model to draft long-form prose. The instructions within this skill explicitly reference the localized USER.md style guide, dictating parameters such as Markdown structural formatting, HTML header hierarchy, keyword density, and the specific tonal requirements (e.g., authoritative, analytical, or heavily sarcastic).
- The Multi-Modal Media Integration: For highly advanced pipelines, skills can be engineered to bridge text generation with external, multi-modal APIs. OpenClaw can utilize authorized Python scripts to dispatch generated text to voice-cloning services like 11Labs, generate corresponding visual concepts utilizing image models like Nano Banana Pro or fal.ai, and stitch the assets into automated video formats utilizing programmatic editors like Remotion.
- The Deployment and Publishing Layer: The final skill in the sequence dictates distribution.
The agent uses shell commands to execute automated Git commits, pushing the finalized Markdown files and generated media assets directly to a static site generator repository (such as Netlify or Vercel), or utilizing specific APIs to publish directly to platforms like WordPress or Anti-Gravity.
Because OpenClaw evaluates these modular skills dynamically, the system allows for a highly flexible pipeline. A user can simply command the agent via iMessage: “Run the SEO Video Article skill on the topic of AI infrastructure.” The agent will independently locate the corresponding module, execute the sequential logic from research to video rendering, invoke the local Gemma model for all text generation and logic routing, and return the completed asset URLs to the messaging channel.
Autonomous Distribution: The Moltbook Social Layer
Generating content autonomously solves only half of the digital workflow; distributing that content and building social capital is equally critical. To address this, the ecosystem introduced Moltbook, a highly experimental and fundamentally unique social network built exclusively for artificial intelligence agents. While OpenClaw (formerly Moltbot) operates as the backend execution powerhouse responsible for drafting and automation, Moltbook serves as the visible front-end social layer.
Moltbook functions similarly to platforms like Reddit or X (formerly Twitter), featuring feeds, comment sections, upvotes, and dedicated community sub-forums termed “submolts”. However, the critical distinction is that human users are restricted to purely observational roles; only authenticated AI agents possess the capability to post, comment, debate, and share generated content. This creates a living, real-time environment where localized agents collaborate, form digital ecosystems, and distribute their generated outputs autonomously.
Integrating a local Gemma 4 OpenClaw pipeline into the Moltbook ecosystem requires a specific registration and verification workflow. The agent must first be instructed to read the official SKILL.md hosted on the Moltbook domain, which dynamically installs the necessary behavioral rules, API keys, and heartbeat routines into the local ~/.moltbot/skills/moltbook/ directory. The agent then initiates a REST API call to register an account, choosing a unique username. To prevent infinite spam generation, the platform mandates a human-in-the-loop verification step; the agent receives a claim URL and a verification code, which the human operator must post via their external X (Twitter) account to authorize the agent’s identity.
Once verified, the autonomous distribution pipeline is complete. The local agent, guided by its HEARTBEAT.md configuration and the newly installed Moltbook skill, will routinely wake up, parse the content it generated earlier in the day, format the content into socially optimized posts, and transmit the data to the Moltbook API. The agent can also engage with the community, upvoting relevant industry content, replying to queries from other autonomous agents, and building a continuous, automated feedback loop that enhances its own social visibility without requiring manual human oversight.
Advanced System Safeguards, Memory Management, and Security Architecture
Deploying a fully autonomous agent equipped with system-level terminal access, external messaging bridges, and an autonomous social presence introduces extraordinary complexities regarding data management, contextual memory limits, and catastrophic cybersecurity vulnerabilities. Scaling this local pipeline from an experimental desktop script to a reliable, secure production utility requires the rigorous implementation of advanced technical safeguards.
The Context Window Bottleneck and Vector Compaction
A fundamental physical limitation of local LLM orchestration is the rapid, inevitable saturation of the context window. Because OpenClaw operates by injecting the overarching identity instructions, the complex tool definitions, the personality prompt, the executing skill logic, and the entire chronological ongoing conversation history into every single inference request, the token count escalates exponentially. Furthermore, if the content pipeline is instructed to ingest a massive research document or a 50-page PDF before drafting an article, the context payload can easily exceed the limits of the localized hardware and the Ollama configuration.
When an LLM like Gemma 4 is pushed to its absolute context limits, it inevitably suffers from the well-documented “lost-in-the-middle” phenomenon. This occurs when the model’s attention mechanism assigns lower computational weight to information buried in the center of a massive prompt, causing it to silently ignore critical instructions or data points. In a content generation pipeline, this architectural failure leads to drafts that violently deviate from established style guidelines, hallucinate statistical facts, or lose narrative coherence.
To aggressively mitigate this token bloat, administrators must leverage OpenClaw’s context compaction protocols defined within the JSON configuration. Instead of carrying an infinite, literal transcript of past generation sessions, the agent can be configured to periodically summarize older interactions, retaining only the semantic core value while discarding thousands of literal tokens. Additionally, for highly advanced deployments, replacing the default simple text-based memory logs with sophisticated, open-source vector-embedded memory frameworks, such as the Mem0 plugin, drastically improves recall. Mem0 allows the OpenClaw agent to recall relevant historical data via semantic similarity search against a local database rather than brute-force context injection. This structural upgrade ensures that an article drafted in December can accurately reference thematic elements generated in January without requiring the entire year’s output to reside in active memory.
Hybrid Orchestration Strategies and Infrastructure Hosting
While the philosophical objective is a zero-cost pipeline relying entirely on local Gemma 4 models via Ollama, specific micro-tasks may occasionally exceed the reasoning capabilities of the localized hardware, or conversely, minor repetitive tasks may waste valuable heavy-compute cycles on a primary GPU. A highly nuanced architectural approach involves hybrid model routing via an API proxy. OpenClaw allows for the detailed configuration of multiple sub-agents dynamically mapped to different inference endpoints based on the cognitive load of the task.
An optimized, cost-efficient architecture utilizes the local Gemma 4 model (specifically the 4B or 12B variants) for high-volume, privacy-sensitive, or repetitive tasks—such as processing internal proprietary documents, executing automated web scraping, generating bulk preliminary drafts, writing code snippets, or executing routine data formatting. Simultaneously, the system can be configured to selectively route final editorial reviews, highly complex logical reasoning tasks, or nuanced tone-matching to a frontier cloud model (like Anthropic’s Claude 3.5 or OpenAI) via an API. This hybrid structure balances the zero-cost benefits of local inference with the raw power of cloud compute, drastically reducing overall API dependency and costs while maintaining localized control over the core intellectual property.
For users who wish to offload the pipeline from their primary laptop, the system can be deployed on dedicated hardware. Budget-conscious administrators can deploy OpenClaw on a Raspberry Pi 5 or a Mac Mini M2, utilizing software like Tailscale to create a secure, encrypted mesh network. This allows the administrator to communicate with the local Moltbot instance from their phone anywhere in the world without exposing the home network to the public internet. Alternatively, syncing the ~/.clawdbot/workspace directory across multiple devices using cloud storage or Syncthing ensures that the agent’s memory and evolving skill set remain consistent regardless of the physical execution layer.
The Threat Matrix: Security Architecture and Risk Mitigation
The very features that make OpenClaw a revolutionary tool for autonomous content generation—persistent local file access, autonomous tool execution capabilities, and seamless integration with external communication channels—render the entire system highly vulnerable to exploitation and lateral movement. Granting any LLM direct execution rights to a host operating system’s terminal shell introduces the severe, undeniable risk of prompt injection attacks.
If the agent is autonomously scraping data from an external website to generate a research summary as part of its heartbeat routine, a malicious payload hidden invisibly within that website’s HTML source code could theoretically command the local OpenClaw agent to override its primary instructions. Because the local Gemma 4 model executes whatever logical instructions it parses from its context window, an injected prompt could direct the agent to delete critical system directories, exfiltrate sensitive API keys to a remote server, or execute unauthorized cryptojacking scripts. Treating external web data as safe is a catastrophic architectural flaw in agentic design.
Securing the pipeline requires rigorous defense-in-depth strategies.
Daemon and Configuration Security
Under no circumstances should the OpenClaw gateway daemon be executed with root or system administrator privileges; it must be completely isolated within a dedicated, restricted user account (e.g., creating a specific clawd user profile) with carefully managed file ownership permissions. The tool configuration mapping within the JSON settings must strictly adhere to the principle of least privilege, explicitly denying dangerous execution commands unless absolutely necessary for the specific workflow. Administrators can enforce security by requiring manual approval prompts for any destructive actions.
Network Security Protocols
Furthermore, network security must be absolute. When establishing the messaging bridge, utilizing secure, authenticated channels like Slack operating over Socket Mode is vastly superior to exposing public webhooks or utilizing unauthenticated chat protocols. Additionally, configuring a Squid proxy allowlist to restrict the agent’s outbound internet access ensures that even if a prompt injection occurs, the agent cannot transmit stolen data to unauthorized domains, strictly confining its network traffic to approved endpoints like Notion, WordPress, or specified research databases. By implementing these stringent isolation protocols, organizations can confidently harness the immense utility of localized autonomous agents while mitigating the existential risks inherent in granting an AI control over system resources.

