Failsafe API Workflows: Content Calendar Automation Guide
Bridging Spreadsheets and Socials: Building Failsafe API Workflows for Content Calendars

The modernization of digital marketing operations frequently relies on bridging accessible, user-friendly planning interfaces with complex, highly distributed backend systems. Content calendars housed in spreadsheet environments, such as Google Sheets or Microsoft Excel, offer unparalleled flexibility and collaborative ease for editorial teams. However, connecting these static grids to dynamic, highly regulated social media Application Programming Interfaces (APIs) introduces significant architectural and operational challenges. The transition from a manual publishing schedule to a fully automated, programmatic pipeline requires overcoming distributed system failures, including rate limit exhaustion, token expiration, transient network timeouts, and undocumented platform schema alterations.
Developing a failsafe API workflow necessitates shifting the perspective of a spreadsheet from a simple document to a transactional state machine. It requires implementing robust middleware topologies, adhering to strict payload validation rules, and engineering resilient queue-worker patterns equipped with exponential backoff and jitter mechanisms. Furthermore, as social platforms continuously evolve their infrastructural rules—evidenced by the 2026 shifts in X’s (formerly Twitter) consumption-based billing, Meta’s metric deprecations, and TikTok’s stringent media chunking requirements—the underlying automation must be designed to adapt dynamically without cascading failures.
This comprehensive report provides an exhaustive analysis of the protocols, platform-specific constraints, and engineering paradigms required to construct highly reliable, automated content publishing pipelines in the modern digital landscape.

The Spreadsheet as a Transactional State Machine
To function as the origin point for a programmatic publishing pipeline, a spreadsheet must be rigidly structured to enforce transactional integrity. Without strict controls, human input errors—such as malformed URLs, excessive character counts, or invalid media types—will inevitably trigger downstream API rejections, clogging the automation queue and leading to silent failures. A resilient architecture begins at the data entry phase, treating the spreadsheet not as a free-text canvas, but as a rigid relational database.
Enforcing Pre-Flight Data Validation
The first line of defense in a failsafe workflow is pre-flight validation occurring directly within the spreadsheet environment. This ensures that no payload is transmitted to the integration layer unless it perfectly conforms to the target platform’s specifications. If a user attempts to input data that violates an API schema, the spreadsheet should block the input or flag it immediately, preventing the workflow from initiating a doomed HTTP request.
Native spreadsheet functions provide the foundational validation layer. Character counting, which is critical due to disparate limits across social platforms, requires precise execution. Standard =LEN() functions calculate absolute string lengths, but user inputs frequently contain hidden trailing spaces resulting from copy-pasting operations. Utilizing =LEN(TRIM(A2)) ensures accurate character counts by omitting erroneous whitespace, preventing edge-case rejections when a payload is exactly at the character limit. For bulk evaluation across ranges, array formulas such as =ArrayFormula(SUM(LEN(A2:A6))) aggregate total payload sizes to ensure they do not exceed batch processing limits.
Temporal data presents another severe failure point. Social media APIs universally demand strict adherence to ISO 8601 date and time formatting (e.g., 2026-11-22T13:37:00Z). Standard spreadsheet date formats often default to local locales, leading to scheduling discrepancies, missed publishing windows, or outright API rejections. Implementing custom validation rules or utilizing Google Apps Script to parse and enforce ISO 8601 structures prevents the transmission of malformed scheduling timestamps. Best practices dictate storing all temporal data in Coordinated Universal Time (UTC) at the database layer and only converting to local time zones at the visualization layer to prevent Daylight Saving Time (DST) edge-case failures.
Dynamic Validation via Apps Script and Macros
For complex pre-flight checks, Google Apps Script and Excel Power Automate allow the execution of custom logic prior to workflow initiation. Two critical validations required for social media publishing are URL resolution and Multipurpose Internet Mail Extensions (MIME) type verification.
When a content calendar includes links to external media assets (e.g., images or videos hosted on AWS S3, Google Drive, or Dropbox), the workflow must verify that the URL is publicly accessible and points to an accepted file format before attempting to pass that URL to a social media API. Apps Script utilizing the UrlFetchApp service can issue lightweight HTTP HEAD requests to validate media links, ensuring a 200 OK status is returned rather than a 404 Not Found or 403 Forbidden.
Furthermore, checking the MIME type ensures the asset aligns with platform capabilities. By inspecting the Content-Type header of the fetch response, or by utilizing the MimeType enum in Google Drive environments (e.g., MimeType.JPEG, MimeType.MP4), the script can proactively block payloads containing unsupported formats. For instance, if a user attempts to schedule a .png file for a TikTok image post, the script will reject the entry because TikTok explicitly requires JPG, JPEG, or WEBP formats for images and does not accept PNG media files.
Implementing Concurrency Control and State Tracking
A spreadsheet acting as a database lacks native ACID (Atomicity, Consistency, Isolation, Durability) properties. To prevent race conditions—such as a scheduled script picking up the same row twice and resulting in duplicate posts, which can trigger spam filters and API bans—the spreadsheet must implement a robust state machine architecture.
This requires dedicated columns acting as system metadata, strictly controlled by programmatic rules rather than manual entry:
- Status: Transitions through deterministic states (e.g., DRAFT, IN_REVIEW, APPROVED, QUEUED, PROCESSING, PUBLISHED, FAILED).
- Lock_Timestamp: Records the exact epoch time a middleware process picks up the row, preventing concurrent worker execution.
- Retry_Count: Tracks the number of delivery attempts to enforce bounded retries and prevent infinite loops.
- Platform_Post_ID: Stores the specific unique identifier returned by the API upon successful publication, serving as a foreign key for future programmatic interactions (e.g., comment moderation, engagement analytics, or deletion).
By designing the workflow so that the integration middleware only queries rows where Status = ‘APPROVED’ and the Lock_Timestamp is null, the system mimics an optimistic concurrency control mechanism. Once the payload is picked up, the middleware immediately updates the status to PROCESSING and sets the timestamp, ensuring idempotency in the publishing sequence and preventing duplicate content generation.
Middleware Topologies: Orchestration and Execution Layers
Extracting data from the spreadsheet state machine and routing it to destination APIs requires a dedicated middleware layer. The 2026 landscape offers a broad spectrum of solutions ranging from fully managed Integration Platform as a Service (iPaaS) solutions to custom-coded microservices. Choosing the correct architecture dictates the reliability, maintenance burden, security compliance, and scalability of the automated social media publishing pipeline.
Comparative Analysis of Orchestration Architectures
Different organizational scales demand different middleware approaches. The decision matrix typically involves evaluating ease of use against granular control and cost-at-scale.
| Architectural Solution | Execution Model & Logic | Error Handling Capabilities | Scalability & Cost Dynamics | Maintenance & Security Burden |
|---|---|---|---|---|
| Zapier | Linear, task-based execution. Simple trigger-action models. | Basic automated retries; limited programmatic routing. | High cost at volume. Task-based billing accelerates quickly. | Minimal. Provider maintains API connections and OAuth security. |
| Make (formerly Integromat) | Visual branching, operations-based billing, complex iterators. | Advanced built-in modules (Break, Resume, Rollback). | Highly cost-effective for multi-path logic. | Low. Visual debugging and version control logs available. |
| n8n (Self-Hosted) | Node-based workflow canvas with programmatic expressions. | Highly programmable try/catch nodes; deep JavaScript support. | Infrastructure cost only. Unlimited operations. | High. Requires server maintenance, database patching, and monitoring. |
| Custom API Services (Node.js/Python) | Fully programmatic queue-worker architecture (SQS, Celery). | Absolute control over headers, Circuit Breakers, and DLQs. | Highest initial development cost; lowest marginal cost at scale. | Highest. |
Demands manual API version tracking, token rotation, and patching.
Zapier provides an unparalleled ecosystem with over 8,000 integrations, making it highly accessible for rapid deployment. However, its task-based billing and primarily linear workflow execution make it fragile and expensive for complex social media publishing where intricate branching logic is required (e.g., posting an image to Instagram, but altering the payload to send the exact same text as a threaded conversation to X). Zapier’s error handling relies heavily on automated replays rather than granular, programmatic recovery routing, which can lead to unpredictable behaviors during sustained API outages.
Make (formerly Integromat) operates on a visual canvas that excels in parallel processing and data transformation. It features specialized error-handling nodes that are vital for failsafe workflows. For instance, if an API call to LinkedIn times out, Make can utilize a Resume node to substitute fallback data, or a Break node to halt the scenario, store the incomplete execution, and automatically retry it later without data loss. Make’s operation-based pricing is generally more cost-effective at scale for complex routing compared to Zapier.
n8n offers a sophisticated bridge between low-code ease and custom development depth. Because it can be self-hosted, it bypasses SaaS execution limits, providing unrestricted operations and making it highly attractive for extreme-volume publishing. It is particularly effective for workflows heavily reliant on custom HTTP requests and complex JSON parsing. However, this flexibility shifts the burden of infrastructure maintenance, scaling, and security patching directly onto the internal DevOps team.
Custom API Architecture represents the most resilient but resource-intensive approach. Utilizing languages like Python, Go, or Node.js alongside cloud-native infrastructure (e.g., AWS Lambda, Amazon SQS, or Apache Kafka) provides total control over timeout tolerances, retry strategies, and persistent OAuth token management. While iPaaS solutions abstract the underlying HTTP requests, custom integrations allow engineers to interact directly with response headers—such as extracting the X-Rate-Limit-Remaining parameter to dynamically throttle the worker node proactively before a rate limit violation occurs.
Payload Validation and Asset Processing Protocols
Once the middleware extracts the data from the spreadsheet, it must format the payload to meet the destination’s requirements. Social media platforms do not share a unified data model. An image size that is perfectly acceptable for LinkedIn may trigger a severe error on X. Therefore, the middleware must act as an intelligent translation and validation layer.
Character Limitations and Text Processing
Character counting algorithms must account for platform-specific parsing rules. For example, while standard text limits apply, the treatment of URLs and mentions varies.
| Platform | Text Character Limit | URL Handling | Special Considerations |
|---|---|---|---|
| X (Twitter) | 280 (Free/Standard), 25,000 (Premium) | Shortened to 23 characters regardless of actual length. | Error 186 triggered if limits are breached. Duplicate text triggers Error 187. |
| 2,200 | Not clickable in standard captions. | Only the first ~125 characters display before the “more” truncation. Max 30 hashtags. | |
| 3,000 (Posts), 1,250 (Comments) | Clickable; often generates preview cards. | 400 Bad Request if payload violates schema limits. | |
| TikTok | 2,200 | Not natively clickable in standard descriptions. | Description length includes hashtags. Spam filters triggered by repetitive text. |
| 63,206 | Clickable; generates preview metadata. | Optimal engagement requires much shorter text despite the massive technical limit. |
The middleware must truncate text intelligently, ensuring that URLs or critical hashtags are not severed midway, which would result in dead links or broken categorization.
Media Transcoding and Delivery Specifications
Handling media programmatically introduces immense complexity. APIs enforce rigid guidelines on file sizes, codecs, aspect ratios, and bitrates. If a spreadsheet contains a link to a 4K video, the middleware may need to pass that URL through a transcoding service (such as AWS Elemental MediaConvert) before submitting it to the social platform.
| Specification | X (Twitter) | TikTok | Meta (Facebook) | |
|---|---|---|---|---|
| Max Video Size | 512 MB | 5 GB | 4 GB | 10 GB |
| Max Duration | 140 seconds | 30 minutes | 10 minutes (via API) | 240 minutes |
| Allowed Formats | MP4, MOV, M4V | MP4 | MP4, WebM, MOV | MP4, MOV |
| Resolution/Ratio | Min 32x32, Max 1920x1920. Ratio 1:3 to 3:1 | Aspect Ratios defined by Height/Width integers | Min 360px, Max 4096px. 9:16 highly recommended | Varies by placement |
| Max Assets/Post | 4 photos OR 1 video OR 1 GIF | 1 video OR multiple images | 1 video OR up to 35 images | Multiple mixed assets |
Failure to adhere to these constraints will result in HTTP 400 Bad Request or 422 Unprocessable Entity responses. Furthermore, media uploads to APIs are rarely synchronous. As detailed in the platform-specific sections below, platforms require chunked uploads, initialization phases, and asynchronous processing verification to handle the heavy bandwidth requirements of modern video.
Managing OAuth 2.0 and Token Lifecycle Automation
A primary vulnerability in automated API integrations is the “Forever Token” fallacy. Developers often assume that once a user authenticates a platform, the resulting access token remains valid indefinitely. In reality, modern security architectures heavily rely on short-lived access tokens to minimize the attack surface in the event of a credential leak. When building a failsafe content calendar, server-side applications must implement automated token rotation and lifecycle management.
Token Decay and Refresh Strategies
When dealing with OAuth 2.0 and social API integration, tokens possess wildly different lifespans. For instance, short-lived Meta tokens expire within 1 to 2 hours. Attempting to use an expired token will yield an OAuthException (Error 190 on Meta, or invalid_grant on LinkedIn).
To maintain persistent automation without requiring the end-user to manually log in every day, the backend must securely store both the short-lived access token and the long-lived refresh token.
- Proactive Refreshing: The most resilient approach is proactive monitoring. The system database stores the exact epoch timestamp of token expiration. A scheduled background worker (cron job) queries the database for tokens expiring within a specific threshold (e.g., 24 hours) and issues a refresh request to the authorization server before the token dies.
- Reactive Refreshing: Alternatively, the middleware intercepts the 401 Unauthorized response. Instead of failing the spreadsheet row, the error handler pauses the publishing task, executes the refresh flow using the stored refresh token to obtain a new access token, updates the database, and then replays the original publishing request.
Race Conditions and Token Family Revocation
Implementing reactive token refreshing in highly concurrent systems introduces a critical risk: race conditions. If three separate publishing workers pick up three different spreadsheet rows for the same social account simultaneously, and all three detect a 401 Unauthorized error, they may all attempt to refresh the token at the exact same millisecond.
Modern OAuth 2.0 providers implement Refresh Token Rotation with Reuse Detection. When a refresh token is used, it is invalidated, and a new one is issued. If a provider detects that an already-used refresh token is submitted again (which happens during a race condition), it assumes the token has been compromised. The provider will then instantly revoke the entire token family, permanently severing the API connection until a human re-authenticates the application.
To prevent this, middleware must utilize atomic database locks or distributed caching (like Redis) during the refresh flow. When Worker A begins the refresh process, it places a lock on the account credentials. Workers B and C must wait for the lock to release, at which point they will retrieve the newly minted token from the database rather than attempting their own refresh.
Platform-Specific API Dynamics and Constraints (The 2026 Landscape)
Regardless of the middleware chosen or the token strategy implemented, the publishing workflow is bound by the strict architectural idiosyncrasies of the destination platforms. Social media APIs are notoriously volatile, frequently deprecating endpoints, altering billing models, and shifting authentication paradigms.
Meta Graph API (Facebook and Instagram)
Meta’s infrastructure requires navigating complex permission scopes and dual-layered rate limiting. Integrations interacting with the Instagram Graph API demand the instagram_content_publish scope, while Facebook requires pages_manage_posts.
As noted, Meta utilizes a token exchange flow.
The workflow must trade short-lived tokens for long-lived tokens via the fb_exchange_token grant type, extending validity to approximately 60 days. If this 60-day window expires, the token cannot be refreshed programmatically; it requires manual user re-authorization.
Rate limiting on the Graph API operates on both Platform Rate Limits (for user/app tokens) and Business Use Case (BUC) Rate Limits (for system users). For the Instagram Content Publishing API, the standard quota is strictly capped at 200 requests per hour per user. Exceeding this triggers a 429 Rate Limited response, requiring the implementation of exponential backoff.
Meta enforces specific error taxonomies that middleware must parse:
- Code 190 (OAuthException): Token is expired, revoked, or invalid. Triggers the refresh flow or alerts for manual login.
- Code 200 (Permissions Error): The app lacks required scopes (e.g., trying to publish to a page without admin rights).
- Code 100 (Invalid Parameter): Malformed request, missing required parameters, or invalid media types.
In a notable 2026 shift, Meta officially deprecated several legacy analytics endpoints. Metrics such as video_views (for non-Reels content), profile_views, website_clicks, and story_impressions were removed to unify cross-platform measurement under a standardized “Views” metric. Workflows tracking post-publication analytics back into the spreadsheet must be updated to reference these new schemas to prevent 404 Not Found or 100 Invalid Parameter errors.
X (Twitter) API v2
The X API underwent radical architectural and commercial transformations. Moving away from the generous free tiers of the past, early 2026 saw X shift toward a pay-as-you-go, consumption-based billing model, bridging the gap between the severely limited Free tier and the extremely expensive Enterprise tiers.
Publishing media via the X API v2 requires a distinct, multi-step orchestration. The legacy v1.1 media upload endpoints were deprecated, meaning simple single-shot media uploads are no longer viable. The workflow must orchestrate a sequence utilizing the INIT, APPEND, and FINALIZE endpoints.
- INIT: The middleware requests to start an upload, providing the total byte size and MIME type. X returns a media_id.
- APPEND: The middleware chunks the binary data and uploads it using the media_id.
- FINALIZE: The middleware signals the upload is complete. X processes the video asynchronously.
- POST: Only after the media is fully processed can the media_id be attached to the actual POST /2/tweets request to publish the content.
Rate limits on X are rigidly enforced through 15-minute rolling windows for paid tiers and strict 24-hour windows for free tiers. A 429 Too Many Requests error requires the middleware to parse the HTTP response headers (specifically the reset timestamp) to determine the exact epoch time when operations can safely resume, avoiding unnecessary polling that could lead to IP blacklisting.
LinkedIn Marketing API
LinkedIn enforces strict versioning and deprecation timelines for its REST API. API versions operate on a rigid lifecycle; for example, an API version released in March 2025 (v202503) is completely sunset by March 16, 2026, returning a 426 Version Header is Deprecated error if queried. Failsafe workflows must dynamically update the X-Restli-Protocol-Version and API version headers in their codebases to prevent sudden breakage.
In terms of media, LinkedIn replaced the legacy Assets API with dedicated Videos and Images APIs to simplify the schema for User-Generated Content (UGC). Workflows uploading video must ensure MP4 formatting, with files ranging from 75KB up to 5GB, lasting between 3 seconds and 30 minutes.
Authentication on LinkedIn typically utilizes OAuth 2.0 with access tokens valid for 60 days. However, programmatic refresh tokens with a one-year lifespan are available to approved partners, allowing silent, server-side renewals via the /oauth/v2/accessToken endpoint using the refresh_token grant type. If a token is revoked by the user, or if LinkedIn invalidates it for security reasons, the API returns an invalid_grant error, which the workflow must trap and escalate for manual intervention.
TikTok Content Posting API
TikTok’s architecture splits publishing into two distinct paradigms: the Direct Post API (which publishes immediately to the public profile) and the Upload API (which sends content to a user’s inbox as a draft for final manual editing).
Media transfer to TikTok requires meticulous byte management and chunking logic. For videos exceeding 64MB, the API mandates chunked uploads. The middleware must calculate the total_chunk_count by dividing the video_size by the chunk_size. Each chunk must be a minimum of 5MB and a maximum of 64MB, transmitted sequentially using HTTP PUT requests with strict Content-Range headers (e.g., Content-Range: bytes 0-30567099/30567100).
Furthermore, TikTok operates highly asynchronously. Because content must pass through TikTok’s sophisticated Trust and Safety (TnS) moderation layer and copyright checks, the initial API call simply queues the media. The workflow must not assume the post is live. Instead, it must either poll the /v2/post/publish/status/fetch/ endpoint or, preferably, listen for incoming webhooks (e.g., post.publish.complete or post.publish.failed) to confirm successful publication and retrieve the final post_id. If the content violates policies, the API will return specific errors like spam_risk_too_many_posts (hitting the daily cap) or spam_risk (content rejected by moderation), indicating a terminal failure where retries should not be attempted.
Engineering Fault Tolerance: Exponential Backoff, Jitter, and Queues
When scaling social media automation across thousands of spreadsheet rows and multiple platforms, failures are not anomalies; they are statistical certainties. Network latency, temporary platform outages, and rate limit exhaustion will inevitably occur. A failsafe architecture does not attempt to prevent all errors, but rather is engineered to degrade gracefully and recover automatically without human intervention.
Categorizing HTTP Responses for Intelligent Routing
Not all API failures warrant a retry. Blindly re-transmitting failed requests amplifies system load, wastes computing resources, and risks permanent IP or application bans. Error handling middleware must classify HTTP response codes to determine the precise routing path:
- Terminal Errors (400, 403, 404, 422): These denote malformed syntax, insufficient permissions, resource not found, or semantic data violations (e.g., trying to publish a 10GB video to an API that only accepts 512MB). Retrying these requests will never succeed. The workflow must immediately mark the spreadsheet row state as FAILED, log the specific exception, and halt execution for that item.
- Authentication Errors: Triggers the token refresh sequence. If the refresh sequence fails (e.g., returning an invalid_grant), the error transitions to a terminal state, requiring human re-authorization.
- Transient Errors (429, 500, 502, 503, 504): These indicate rate limit exhaustion, bad gateways, timeouts, or internal server errors on the social platform’s side. These are the primary candidate events for algorithmic retry mechanisms.
The Mathematics of Exponential Backoff and Jitter
When handling transient errors—particularly 429 Too Many Requests or 503 Service Unavailable—a standard, fixed-interval retry loop (e.g., waiting exactly 5 seconds before trying again) is highly destructive. If a platform experiences a brief outage, thousands of automated clients running fixed retries will attempt to reconnect simultaneously the moment the server comes back online. This creates a “thundering herd” effect that acts as a self-inflicted Distributed Denial of Service (DDoS) attack, immediately knocking the server back offline.
To resolve this, workflows must implement Exponential Backoff. This algorithm progressively increases the wait time between subsequent retry attempts. If the base delay is 1 second, subsequent retries will occur at 2, 4, 8, 16, and 32 seconds. This gives the failing service breathing room to recover.
However, pure exponential backoff still allows for synchronized retries if multiple posts fail at the exact same millisecond. To safely scatter the requests, the algorithm must introduce Jitter—a randomized variance applied to the backoff delay.
By executing this algorithm, the workflow smoothly disperses retry traffic, mitigating system load spikes and allowing the destination API adequate time to recover from traffic surges.
Asynchronous Queue-Worker Architectures
Attempting to run complex, multi-step publishing operations directly from synchronous spreadsheet triggers (like Google Apps Script onEdit functions) inevitably leads to timeout failures. These scripts have strict execution time limits (typically 6 minutes), and waiting for a massive video to transcode and upload will cause the script to crash mid-execution.
A robust architecture decouples the trigger from the execution using a Queue-Worker pattern. When a spreadsheet row is validated and marked APPROVED, a lightweight process immediately captures the payload and drops it into a highly durable message broker (e.g., Amazon SQS, RabbitMQ, or an internal queue within an enterprise iPaaS).
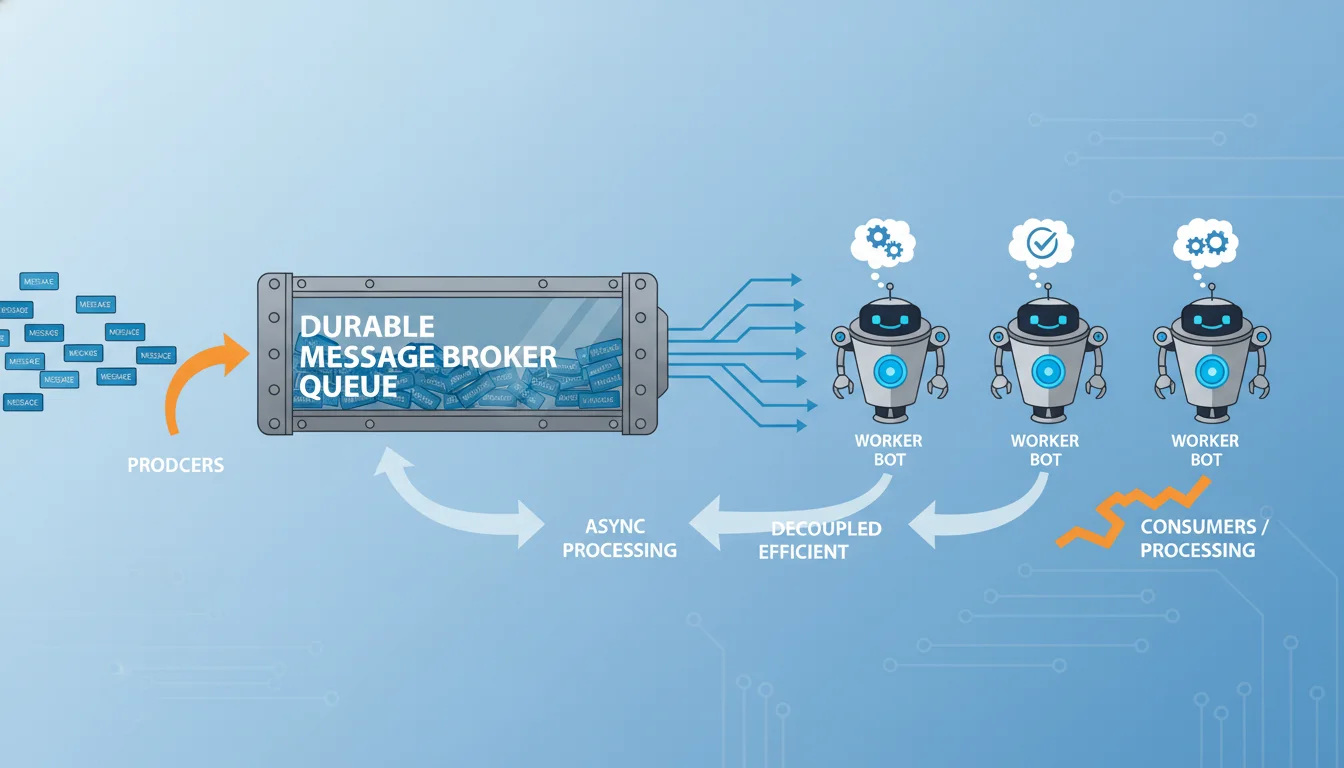
The worker service polls this queue asynchronously.
If an API request fails due to a transient error, the worker does not block the entire system waiting for the backoff timer. Instead, it calculates the exponential backoff delay, updates the message’s visibility timeout (hiding it from other polling workers for the duration of the backoff), and leaves it in the queue for later processing.
If a payload fails repeatedly and exceeds its maximum retry threshold (e.g., 5 attempts), the worker routes the payload to a Dead Letter Queue (DLQ). The DLQ acts as a quarantine zone for “poison pills”—messages that continually fail due to unforeseen edge cases. This isolates the failure, preventing it from clogging the primary publishing pipeline, and allows engineers to inspect the specific malformed payloads manually without halting the rest of the content calendar.
Telemetry, Observability, and Automated Incident Response
Even the most highly engineered, fault-tolerant automation will encounter scenarios requiring human judgment, such as a completely revoked OAuth permission, a platform-wide service degradation, or a sudden change to a platform’s terms of service. Silent failures are the enemy of digital marketing operations. Therefore, the architecture must include comprehensive observability and alerting pipelines.
Error Standardization and Metric Tracking
When an API returns an error, the raw JSON payload is often deeply nested and highly specific to the platform. The middleware must capture these responses and standardize them into a unified format. A robust logging implementation captures the correlation ID provided by the platform (e.g., x-fb-trace-id for Meta, x-li-uuid for LinkedIn, or log_id for TikTok). These unique identifiers are critical when submitting support tickets to platform developer portals, as they allow platform engineers to trace the exact failed transaction through their internal logs.
Using Application Performance Monitoring (APM) tools like Sentry, Datadog, or New Relic allows for the automated ingestion of these stack traces. By monitoring error rates across time windows, these tools can detect systemic anomalies—such as a sudden 400% spike in 401 Unauthorized requests across multiple client accounts—and trigger algorithmic circuit breakers. A circuit breaker temporarily halts all outgoing API requests to a failing service, preventing the system from burning through rate limits while the underlying issue is resolved.
Real-Time Alerting via Slack Webhooks
To complete the failsafe loop, the system must inform the human content team when an unrecoverable (terminal) error occurs. Integrating Slack Incoming Webhooks enables the workflow to push rich, interactive alerts directly to specific communication channels.
To prevent alert fatigue—where developers ignore channels flooded with unreadable error logs—the middleware should construct structured, visually appealing JSON payloads using Slack’s Block Kit API. A standard, highly actionable alert should include:
- The Context: Which spreadsheet row, which brand account, and which platform failed.
- The Exception: The specific HTTP error code and the parsed, human-readable error message directly from the API (e.g., 186: Tweet needs to be a bit shorter or TikTok spam_risk: Content rejected by moderation).
- The Actionable Resolution: A direct hyperlink back to the specific Google Sheet row, allowing the social media manager to immediately correct the text length, update the media URL, or re-authenticate the token, and reset the status to APPROVED to re-enter the queue.
By routing only terminal errors to human operators while allowing the exponential backoff and queue algorithms to silently handle transient network fluctuations, the system maximizes throughput, maintains calendar accuracy, and minimizes developer intervention.
Conclusion
Constructing an automated social media content calendar that connects a ubiquitous spreadsheet interface directly to complex social platform APIs requires an engineering rigor that extends far beyond simple point-to-point webhook connections. As platforms like X, Meta, LinkedIn, and TikTok continuously tighten their rate limits, deprecate legacy endpoints, and enforce increasingly strict media chunking constraints, fragile integrations will rapidly succumb to data loss, authentication decay, and silent failures.
By architecting the spreadsheet as a strict, validation-heavy state machine, and by utilizing decoupled middleware layers equipped with exponential backoff, jitter, and queue-worker isolation, organizations can construct highly resilient publishing engines. When augmented with granular telemetry, automated token lifecycle management, and actionable Slack alerting, these pipelines transition from brittle, high-maintenance scripts into enterprise-grade, failsafe systems capable of managing high-volume, multi-platform content distribution with absolute reliability.


