Automate HubSpot Lead Scoring: APIs, Webhooks & AI
Advanced Automation of Lead Scoring in HubSpot: Integrating Webhooks and Custom APIs
The evolution of customer relationship management architectures has fundamentally shifted how revenue operations prioritize and engage with prospective buyers. Within the HubSpot ecosystem, native lead scoring mechanisms have traditionally provided a foundational capability for aligning marketing and sales efforts. However, as enterprise data topologies mature and the complexity of the buyer journey increases, the limitations of natively confined, rule-based scoring engines become increasingly apparent. Organizations attempting to scale their go-to-market strategies quickly discover that relying solely on manually weighted rules introduces systemic confirmation bias, ignores crucial off-platform telemetry, and struggles with dynamic, time-decaying signal processing. To transcend these structural boundaries, modern revenue operations architectures demand decoupled, highly computational lead scoring systems.

This report provides an exhaustive architectural blueprint for automating advanced lead scoring in HubSpot by leveraging outbound webhooks, external compute environments, and the HubSpot CRM API. The analysis covers the strategic decoupling of data ingestion, the cryptographic validation of webhook payloads, asynchronous queue-driven event processing, predictive scoring computations utilizing artificial intelligence and custom scripts, and optimal synchronization strategies utilizing batch API endpoints.
The Strategic Imperative for Decoupled Lead Scoring
Native lead scoring in HubSpot relies on a manual, points-based framework that operates entirely within the confines of CRM data. Administrators configure engagement and fit criteria using “if/then” logic, where specific property values or tracked actions incrementally add or subtract points from a default 100-point ceiling. While functional for basic implementations, this paradigm exhibits severe limitations in complex enterprise environments.
The Limitations of Native Architectures and Confirmation Bias
Manual scoring mechanisms intrinsically suffer from confirmation bias. When marketing and sales teams define the Ideal Customer Profile based purely on historical intuition and legacy conversion data, the scoring algorithm continuously rewards leads that fit the pre-existing belief system while inadvertently suppressing potentially lucrative outliers. If there are systemic errors in the hypothesized profile, the lead scoring mechanism operates as a reinforcing feedback loop, continuously qualifying the wrong prospects and degrading the efficiency of the sales pipeline. Predictive lead scoring partially mitigates this by analyzing existing customer data, but it remains fundamentally bounded by the data explicitly existing within the HubSpot CRM.
Modern buyer journeys generate immense telemetry across dispersed platforms. A high-intent prospect may exhibit signals across product usage applications, external billing systems, support ticketing platforms, and third-party data enrichment services. Integrating these external data points into native HubSpot scoring requires constant synchronization of hundreds of custom properties, which heavily degrades CRM performance, consumes API limits, and clutters the database schema.
Dynamic Decay and Negative Scoring Nuances
Furthermore, native scoring environments often struggle with sophisticated negative scoring and continuous time-decay logic. Negative scoring is essential for maintaining accuracy; leads who are students, employees of a competitor, or utilizing generic freemail domains must be systematically deprioritized. While HubSpot allows administrators to assign negative point values to static properties, implementing dynamic decay—where a highly engaged lead gradually loses score velocity over time due to inactivity—is highly constrained. Native decay rules are often binary, whereas a decoupled computational environment can apply exponential decay formulas that smoothly degrade a score day over day, ensuring sales teams are not pursuing historically active but currently cold records.
Architectural Foundations: Private Versus Public Application Infrastructure
Before deploying a custom lead scoring engine, the infrastructure connecting the external compute environment to HubSpot must be definitively architected. HubSpot provides two primary avenues for API integration: Public Apps authenticated via OAuth 2.0, and Private Apps authenticated via static access tokens. The strategic selection between these two paradigms dictates the security model, rate limits, and functional schema modification capabilities of the integration.
Private Applications and Static Authentication Models
For organizations developing an internal lead scoring system dedicated to a single HubSpot account, the Private App model provides a highly streamlined, secure, and performant architecture. Private apps authenticate using a static access token provided via the Bearer HTTP authorization header. Because these tokens do not expire, the overhead of constructing and maintaining an OAuth refresh token lifecycle backend is entirely eliminated.
Private apps are inherently restricted to the portal in which they are created, but they operate with an isolated, dedicated burst limit. While all private apps within a given HubSpot account share the overarching daily API limit, each individual private app retains a dedicated burst threshold. For example, an Enterprise account provides a private app with a burst limit of 190 requests per 10 seconds, while Free and Starter tiers allow 100 requests per 10 seconds. Furthermore, private apps natively support deep access to custom objects, custom property schemas, and complex pipeline management capabilities that are not fully exposed or easily provisioned through standard public app scopes. This allows internal data teams to programmatically construct the custom property infrastructure required to store complex scoring outputs directly via the API.
Public Applications and OAuth 2.0 Architectures
Conversely, if the custom lead scoring architecture is designed for multi-tenant deployment—such as a revenue operations agency standardizing scoring models across multiple client portals or an independent software vendor distributing a predictive scoring application on the HubSpot Marketplace—a Public App distributed via OAuth is mandatory. The OAuth architecture relies on short-lived access tokens, which expire every 30 minutes, and persistent refresh tokens, necessitating a robust backend service to handle continuous token rotation and multi-tenant authorization flows. Setting up this infrastructure often requires deploying an OAuth backend service hosted in a Docker instance to manage the state and persistence of authentication credentials for each installed portal.
Public apps are subject to a strict per-account burst limit of 110 requests every 10 seconds, which excludes the Search API. Furthermore, public apps face constraints when interacting with portal-specific structures; they cannot natively provision pipelines, pipeline stages, or custom object schemas without highly specific scopes and client-side administrative interventions.
Thus, for a purely internal, enterprise-grade lead scoring system, the Private App infrastructure is heavily favored due to its robust burst limits, unexpiring authentication mechanisms, and deep schema access capabilities.
| Architectural Feature | Private Applications | Public Applications (OAuth 2.0) |
|---|---|---|
| Authentication Strategy | Static Bearer Token | Access & Refresh Tokens |
| Token Lifecycle | Non-expiring (manually rotatable) | 30-minute expiry (automated refresh required) |
| Burst Limit (Enterprise Tier) | 190 requests per 10 seconds (per app) | 110 requests per 10 seconds (per account) |
| Deployment & Distribution Model | Single internal portal | Multi-tenant / HubSpot Marketplace |
| Schema Modification Capabilities | Deep access to custom objects and pipelines | Restricted by specific OAuth permission scopes |
Mathematical Modeling and Algorithmic Scoring
By extracting the computational logic to an external API endpoint—such as an AWS Lambda function, a dedicated Python server, or an AI-driven logic engine—organizations can implement highly sophisticated mathematical models that transcend native capabilities. A modern decoupled lead scoring algorithm generally separates signals into distinct axes: Fit, Engagement, and Decay.
The total score for a specific prospect at any given continuous time variable can be expressed computationally as:
Total Score = Sum (Fiti × WeightFit,i) + Sum (Engagementj × WeightEngagement,j) - Decay
In this framework, the variable Fit represents demographic and firmographic Fit criteria. These criteria evaluate the inherent desirability of the prospect based on attributes such as industry match, total employee count, annual revenue, and the individual’s specific job title. The corresponding weight, WeightFit, determines the magnitude of impact this specific trait has on the overall model. For instance, an organization may assign 25 points for companies exceeding 100 employees and 20 points for alignment with the Software as a Service industry.
The variable Engagement represents behavioral Engagement criteria. This evaluates the prospect’s active interest in the product or service through tracked events, such as marketing email opens, product trial usage, webinar attendance, or pricing page visits. The weight WeightEngagement assigns point values based on the correlation between the behavior and historical conversion rates.
A pricing page visit might yield a 20-point increase, whereas reading a single blog post might warrant only a 3-point increase. Decoupled architectures allow external data, such as a product login event tracked in a proprietary database, to be queried and factored into the calculation without requiring that event to be natively stored in HubSpot.
The final component, , represents the dynamic, time-based mathematical decay function applied to historical engagement. Externalizing this logic allows for the dynamic computation of via exponential decay formulas rather than flat, static subtractions. Furthermore, negative scoring attributes can be injected into the weight parameters if cross-referencing external databases identifies the prospect as a student, competitor, or unqualified entity. AI agents and custom Python scripts can routinely analyze these variables, querying data warehouses like Snowflake or BigQuery to uncover hidden correlations and continuously optimize the weights assigned to each feature.
Event Ingestion Strategies and Webhook Topologies
To initiate the external scoring computation, the custom application must be immediately notified whenever a relevant demographic or behavioral event occurs within the CRM. HubSpot facilitates this event-driven architecture primarily through outbound webhooks. Architecturally, there are two dominant mechanisms to deploy webhooks: Developer App Subscriptions using the Webhooks API, and Operations Hub Workflow Extensions.
Developer App Subscriptions vs. Workflow Webhooks
The Webhooks API allows applications to subscribe to global portal events, such as contact creation, deletion, or specific property changes. The integration creates a subscription, specifying the exact object types and event triggers it wishes to monitor. While powerful for broad, indiscriminate data synchronization across an entire portal, it suffers from a critical lack of payload customization. The webhook triggers across the portal and transmits only the identifiers and the specific changed values, arriving completely devoid of broader context. Consequently, the receiving endpoint must execute a secondary API call back to HubSpot to fetch the necessary ancillary properties required to compute the multi-variable lead score, thereby consuming API limits and introducing significant network latency.
Conversely, utilizing the “Send a webhook” action within HubSpot Workflows offers profound architectural advantages for highly specific lead scoring computations. Available to Operations Hub Professional and Enterprise tiers, workflow webhooks allow administrators to construct highly granular enrollment criteria, ensuring that the scoring engine is only invoked when highly specific, high-value properties change. Most critically, workflow webhooks allow developers to heavily customize the request body payload. The system can be configured to bundle all relevant Fit and Engagement properties into the initial outbound POST request, creating a comprehensive snapshot of the prospect’s current state. This completely eliminates the need for a secondary data-fetching API call, radically improving the speed of the scoring engine and conserving strict API rate limits.
Mitigating Payload Data Type Inconsistencies and Serialization Errors
When customizing the JSON request body in a workflow webhook, software engineers must be acutely aware of severe data type inconsistencies inherent to HubSpot’s internal serialization engine. A documented discrepancy exists between how HubSpot formats properties in standard REST API responses versus how they are transmitted via workflow webhooks utilizing the “Customize request body” feature.
When pulling a contact via the standard CRM API, HubSpot returns virtually all custom property values as JSON Strings. For example, a custom dropdown property might return “some_custom_type”: “111”, and a pipeline stage might return “hs_pipeline_stage”: “555”. However, when these exact same properties are transmitted via a workflow webhook using a customized payload, HubSpot’s serialization engine utilizes deep type inspection and frequently casts these values as JSON Integers. The webhook payload will transmit “some_custom_type”: 111 and “hs_pipeline_stage”: 555 without quotes.
This behavior introduces severe parsing vulnerabilities in statically typed backend environments, such as Java, C, or Go, and can break dynamic parsing logic in Python or Node.js if the downstream code explicitly expects a string. Furthermore, date properties transmitted via standard APIs often appear in ISO 8601 or simplified date strings (e.g., “2024-03-07”), whereas workflow webhooks consistently transmit dates as Unix epoch timestamps in milliseconds (e.g., 1709769600000). Boolean values present another critical vector for failure; if a property is defined as a boolean type in HubSpot, transmitting the literal string “true” instead of the boolean true can cause validation rejections during subsequent updates.
To construct a robust lead scoring integration, the receiving API endpoint must implement a highly defensive deserialization layer. Middleware must be deployed at the network edge to immediately normalize all incoming property values. This involves programmatically casting numerical IDs back to strings, utilizing libraries to convert epoch timestamps to standardized datetime objects, and normalizing boolean values to ensure consistent mathematical operations within the scoring algorithm.
Data Type, Standard API Response Format, Workflow Webhook Payload Format, Required Normalization Strategy
- Numerical Identifiers: Standard API Response Format: JSON String (“123”), Workflow Webhook Payload Format: JSON Integer. Required Normalization Strategy: Middleware must cast to String to prevent type-mismatch errors.
- Date Properties: Standard API Response Format: ISO 8601 String (“2024-03-07”), Workflow Webhook Payload Format: Unix Epoch Milliseconds. Required Normalization Strategy: Parse timestamp into standardized timezone-aware datetime object.
- Boolean Flags: Standard API Response Format: Boolean (true), Workflow Webhook Payload Format: Inconsistent, often String (“true”). Required Normalization Strategy: Strict parsing to true boolean primitives before logic execution.
Cryptographic Security and Signature Validation Protocols
Because the custom scoring API must be exposed to the public internet to receive inbound HubSpot webhooks, securing the endpoint against spoofing, malicious payloads, and unauthorized access is paramount. HubSpot secures outbound webhooks by generating an HMAC SHA-256 signature, which is appended to the request headers. Validating the X-HubSpot-Signature-v3 header is the industry standard for securing modern HubSpot integrations and ensuring data integrity.
The v3 Signature Validation Protocol
The v3 signature represents a significant security enhancement over legacy v1 and v2 implementations by incorporating strict timestamp validation to fundamentally prevent replay attacks. When the custom API receives a payload, it must execute a precise, multi-step cryptographic sequence to verify authenticity before initiating any scoring logic.
- Timestamp Verification: The request will include an X-HubSpot-Request-Timestamp header. The custom application must immediately parse this value and compare it against the receiving server’s current UTC time. If the delta between the two timestamps exceeds 300,000 milliseconds (exactly 5 minutes), the request must be categorically rejected with an HTTP 401 Unauthorized status. This absolute threshold guarantees that payloads intercepted by a malicious third party cannot be re-transmitted at a later date to artificially inflate a lead’s score.
- URI Decoding and Normalization: HubSpot calculates the cryptographic signature based on the exact Target URL configured in the developer portal or workflow webhook settings, inclusive of the protocol. However, the receiving application framework may automatically alter the URI before presenting it to the application code. The application must carefully decode specific URL-encoded characters in the URI to perfectly match HubSpot’s internal hashing logic. Characters such as %3A (colon), %2F (forward slash), %40 (at symbol), %21 (exclamation point), %24 (dollar sign), and %2C (comma) must be strictly decoded. Critically, the question mark (?) designating the beginning of the query parameter string must remain encoded if it was encoded in the source configuration, or remain literal depending on the exact Target URL configuration.
- Source String Concatenation: The backend must construct a UTF-8 encoded source string by concatenating the exact HTTP request variables in a highly specific order. The sequence must combine the HTTP request method, the decoded request URI (including all query parameters in their original, un-shuffled order), the raw unparsed request body, and the timestamp header value. The format is strictly: requestMethod + requestUri + requestBody + timestamp. Utilizing raw unparsed bodies (php://input in PHP or raw body buffers in Node.js) is critical, as automated parsing middleware will alter spacing and invalidate the hash.
- HMAC SHA-256 Hash Generation: Using the application’s unique Client Secret as the cryptographic key, the server generates an HMAC SHA-256 hash of the concatenated source string produced in the previous step.
- Constant-Time Comparison: The resulting hash is Base64 encoded and compared against the value provided in the inbound X-HubSpot-Signature-v3 header. To defend against timing attacks—where an attacker measures the exact microseconds it takes for the server to reject an invalid string to mathematically guess the hash—the comparison must be executed using a constant-time algorithmic function. Standard string equality operators (like == or ===) fail rapidly upon detecting a character mismatch, leaking timing data.
Methods such as crypto.timingSafeEqual in Node.js, hash_equals() in PHP, or MessageDigest.isEqual in Java must be utilized to ensure the comparison takes the exact same amount of compute time regardless of where the mismatch occurs.
Any discrepancy identified during this protocol dictates that the payload may have been tampered with in transit or spoofed by an unauthorized party. In such instances, the server must drop the connection immediately, log the security event, and terminate the execution thread without processing the lead score.
Concurrency, Idempotency, and Asynchronous Queue Management
Processing advanced lead scoring models—especially those invoking complex AI inferences, machine learning algorithms, or querying massive external data warehouses like Snowflake or Redshift—can be highly computationally expensive. This operational reality collides violently with HubSpot’s strict webhook delivery constraints, necessitating a resilient, asynchronous, queue-driven architecture.
Navigating the Strict 5-Second Timeout Paradigm
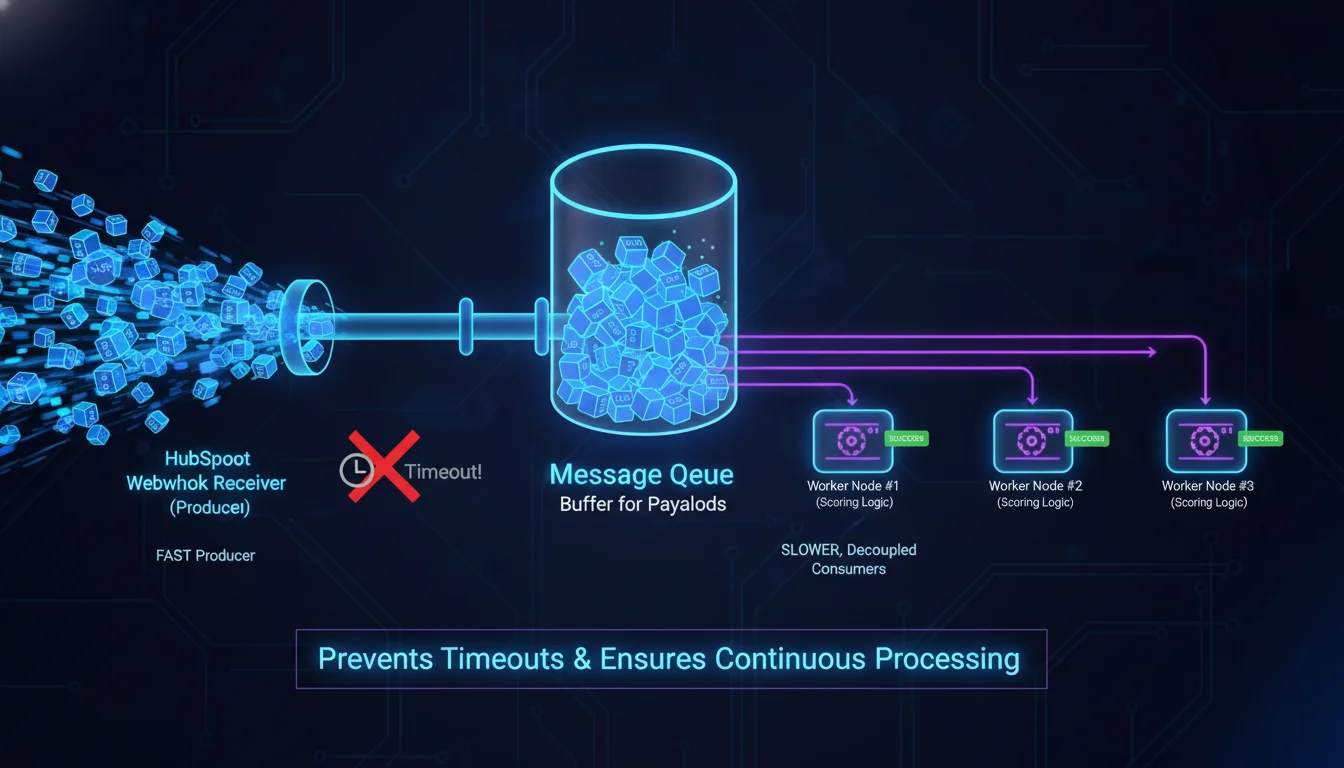
HubSpot enforces an unyielding 5-second timeout on all outbound webhooks, regardless of whether they originate from a Developer App Subscription or an Operations Hub Workflow. If the receiving server does not respond with an HTTP 2xx success code within this exact five-second window, HubSpot registers a timeout failure, severs the connection, and immediately initiates an aggressive retry cascade. It is fundamentally impossible to negotiate or increase this timeout threshold through HubSpot’s settings.
Consequently, attempting to execute the entirety of the lead scoring operation synchronously within the webhook request thread is a critical anti-pattern. Attempting to receive the payload, parse it, query external enrichment APIs, compute the mathematical score, and push the updated score back to HubSpot via the CRM API sequentially will routinely breach the 5-second limit, plunging the integration into an endless cycle of timeouts and duplicated retries.
To circumvent this limitation, the integration must adopt a rigorous producer-consumer architecture. When the webhook payload arrives, the receiving endpoint (the producer) must immediately execute the cryptographic signature validation, serialize the raw JSON payload, push the payload onto an asynchronous message broker queue (e.g., Amazon SQS, RabbitMQ, or a Redis-backed queue like BullMQ), and instantly return an HTTP 200 OK or 202 Accepted response. This ensures the HTTP transaction concludes well within the 5-second threshold, satisfying HubSpot’s delivery requirements and preventing the accumulation of timeout errors. Completely decoupled background worker nodes (the consumers) then independently poll the queue, dequeue the event payload, and process the heavy mathematical scoring logic at their own operational pace without the threat of a timeout severing the execution.
Designing Strictly Idempotent Consumers
Webhook delivery over distributed internet networks guarantees “at least once” delivery, not “exactly once” delivery. HubSpot explicitly documents that duplicate events may be delivered due to transient network blips, intermittent connection resets, or internal platform retry mechanisms. Furthermore, HubSpot features an aggressive retry behavior to ensure data delivery. If a Developer App webhook fails or times out, HubSpot will retry the delivery up to 10 times over a 24-hour period, utilizing randomized delays to spread the load. Workflow webhooks feature an even more persistent retry logic; they will retry failed deliveries for up to three consecutive days. These retries begin approximately one minute after the initial failure, with subsequent intervals increasing until they cap at a maximum gap of eight hours between attempts.
Workflow webhooks will generally not retry on 4xx client errors (such as 400 Bad Request or 401 Unauthorized), recognizing that the payload is inherently flawed or unauthenticated. However, they will aggressively retry on 5xx server errors, network timeouts, or if they receive a 429 Rate Limit error.
Because a lead score calculation inherently relies on additive or subtractive mathematics, processing the identical event twice will permanently corrupt the contact’s total score. If a prospect downloads a whitepaper worth 20 points, and the webhook is delivered three times due to network latency, a poorly designed system will erroneously award the prospect 60 points. Therefore, the consumer processing the asynchronous queue must be strictly idempotent. Idempotency guarantees that applying an operation multiple times has the exact same result as applying it once.
To achieve reliable idempotency, the system must utilize a highly perform performant, distributed storage mechanism—such as Redis, PostgreSQL with unique constraints, or Amazon DynamoDB—to persistently record processed events. Each incoming webhook payload contains identifiers that must be mathematically combined to form a unique, deterministic idempotency key. While HubSpot provides a base eventId, relying solely on this identifier is insufficient. The most bulletproof architectural pattern involves generating a composite key comprising the eventId, the subscriptionType (or the specific workflow ID), and the timestamp or occurredAt value.
Before a worker node computes a lead score, it attempts to insert this composite key into the idempotency database. If the database insertion violates a unique constraint or indicates the key already exists, this confirms the event has already been successfully processed during a previous retry. In this scenario, the worker immediately acknowledges the queue message, discards the payload, and terminates the operation cleanly to prevent duplicate scoring. If the insertion succeeds, the worker proceeds to execute the scoring algorithm. This composite key architecture ensures that even if HubSpot’s retry mechanisms transmit the identical event payload dozens of times, the prospect’s lead score is mathematically updated exactly once.
API Synchronization and CRM Data Mutation Strategies
Once the external compute environment has processed the data, evaluated the decay variables, and determined the new Fit Score, Engagement Score, and total aggregate Lead Score, these numerical values must be written back to the respective contact, company, or deal record within the HubSpot CRM. Efficiently interacting with the HubSpot CRM API to mutate this data is the final, and often most complex, stage of the integration architecture.
Single Record Patching vs. Bulk Synchronization
The HubSpot CRM Properties API enables seamless updating of records. For immediate, real-time synchronization of a single, isolated event, the backend infrastructure can execute an HTTP PATCH request targeting the standard endpoint: /crm/v3/objects/contacts/{contactId}. The payload includes a properties object that maps the internal property names (e.g., hubspot_score, custom_fit_score, last_scoring_event_date) to their newly computed values. If the external scoring system operates purely on email identifiers rather than native HubSpot Record IDs, the API seamlessly supports updating via email by appending the query parameter ?idProperty=email and setting the endpoint URL to /crm/v3/objects/contacts/{email}.
However, executing a discrete HTTP request for every individual score update is highly inefficient at scale and will rapidly consume the portal’s API limits. If an aggressive marketing campaign triggers 5,000 simultaneous “Email Opened” webhook events, processing 5,000 single PATCH requests back to HubSpot will overload the network interface and inevitably trigger a cascade of 429 Too Many Requests responses. Furthermore, processing these updates individually introduces substantial HTTP overhead, slowing the overall throughput of the worker queue.
To optimize network latency, increase throughput, and protect stringent rate limits, the integration must utilize HubSpot’s Batch Update endpoints. The batch update endpoint for contacts (POST /crm/v3/objects/contacts/batch/update) accepts an array of up to 100 object updates in a single HTTP request. The payload is structured as an inputs array, where each element contains the unique id of the record and the specific properties map to update. By grouping operations, the integration reduces network chatter by a factor of 100.
When utilizing batch updates, software engineers must navigate highly specific limitations not present in the single-update endpoints. First, while single updates can easily rely on email addresses for identification, batch updating via a non-unique identifier historically introduces edge cases and parsing complexities. If the batch endpoint requires updating via email instead of the native Record ID, the idProperty field must be explicitly defined as “email” within the JSON structure. The integration must also account for the architectural reality that partial upserts—where the system attempts to update an existing record but creates a new one if it does not exist—are explicitly not supported when using email as the unique identifier in batch contact operations. If a partial upsert is required, a custom unique identifier property must be utilized instead. Second, the system must navigate complexities regarding merged records. If two contact records have been historically merged in HubSpot, developers can normally use the previous, deprecated record ID values stored in the hs_merged_object_ids field to update the unified record using the basic, single-update endpoint. However, these deprecated values are entirely unsupported when updating records using the batch update endpoint. Any batch request attempting to reference a merged ID will fail. Third, error handling within batch requests requires granular, sophisticated attention.
If a single object within a batch update array contains a malformed property, references a deleted record, or violates a schema constraint, the unexpected behavior can disrupt the entire batch processing execution. The API will return an errors object array. The consumer logic must be capable of advanced error parsing to isolate the specific failed records from the array, re-queue those failures for individual analysis, and ensure the valid records within the batch are successfully committed to the database.
Dynamic Property Cleansing and Nullification
Lead scoring algorithms must routinely account for negative attributes degrading to zero, or data points becoming entirely obsolete. When a prospect disengages, or a decay function completely nullifies a score, the system must erase the numerical value from the CRM. The CRM v3 API strictly enforces read-only property parameters and explicitly rejects requests attempting to write to non-existent properties. If a score needs to be entirely erased rather than set to zero, the API allows property values to be cleared by passing an empty string “” as the value in the JSON payload, rather than passing a null primitive. This ensures the CRM database remains unpolluted by legacy integers or artificial zeros that could skew marketing analytics and reporting.
Mastering API Rate Limits and Traffic Throttling
A flawlessly written, highly mathematical scoring algorithm will still fail catastrophically in a production environment if it does not meticulously monitor and manage HubSpot’s dynamic rate limiting architecture. HubSpot APIs are protected by sophisticated token bucket algorithms that strictly regulate inbound traffic based on the portal’s subscription tier, the application distribution model, and the purchased add-ons. Treating the HubSpot API like an unlimited data pipe is the primary reason custom integrations fracture under load.
Decoding Rate Limit Architectures and Header Telemetry
Integrations must constantly monitor API capacity telemetry to avoid dropping crucial score updates or degrading portal performance. A HubSpot application is bound by two intersecting thresholds: the overarching Daily Limit and the high-frequency Burst Limit (measured over rolling 10-second windows). When an API request is successfully executed, HubSpot (with the notable exception of the Search APIs, which possess their own independent limiting behavior) returns distinct HTTP headers detailing the portal’s remaining bandwidth. Advanced integrations must parse these headers on every response:
- X-HubSpot-RateLimit-Daily-Remaining: Dictates the absolute number of requests still allowed for the current 24-hour period. This limit resets automatically at midnight, governed specifically by the portal’s localized timezone settings.
- X-HubSpot-RateLimit-Max: Displays the maximum burst threshold permitted within the current polling interval.
- X-HubSpot-RateLimit-Remaining: The actual number of calls left within the current rolling 10-second timeframe before traffic is blocked.
- X-HubSpot-RateLimit-Interval-Milliseconds: The temporal width of the burst window, typically expressed as 10000 to denote 10 seconds.
Proactive Throttling and 429 Error Protocol Management
The integration’s underlying HTTP client must proactively intercept these headers. If the X-HubSpot-RateLimit-Remaining integer approaches zero, the worker queue must dynamically pause execution. Leveraging an internal throttling library, the integration should sleep the execution threads until the 10-second window expires, subsequently waking the threads and resuming the batch updates without ever triggering an error. If the integration inadvertently breaches the limit, HubSpot will block the request and return a 429 Too Many Requests error. The accompanying JSON response explicitly outlines the policyName, indicating whether the DAILY or the TEN_SECONDLY_ROLLING limit was violated.
Handling a 429 response requires sophisticated, fault-tolerant logic. The application must not indiscriminately throw fatal exceptions that crash the worker node; instead, it should catch the 429 status code and implement an exponential backoff algorithm to safely delay and re-queue the batch update for future execution. In a bidirectional architecture, if the custom endpoint is overloaded by a massive influx of HubSpot webhooks and wishes to rate-limit HubSpot’s delivery mechanism, the endpoint can return its own 429 status. HubSpot’s webhook delivery system natively respects the Retry-After header (provided in milliseconds) returned by the external server, automatically scheduling the payload for later delivery without marking it as a permanent failure.
Furthermore, to maintain app certification and listing privileges within the HubSpot Marketplace, applications must ensure that errors—including 429 rate limits and 5xx network timeouts—do not exceed 5% of the application’s total daily requests. If this threshold is breached, the integration risks decertification.
This strict requirement mandates that batching requests, aggressively caching static settings (such as custom property schemas, pipeline metadata, or record owner IDs) in a fast Redis layer, and deferring all scoring telemetry through webhooks rather than scheduled, polling API requests are strictly enforced architectural requirements. Because inbound webhook invocations routed via Operations Hub workflows explicitly do not count toward the portal’s API rate limits, relying on outbound webhooks to trigger scoring updates is the single most effective strategy for mitigating API exhaustion and ensuring the continuous, flawless operation of the lead scoring engine.
Conclusion
Automating lead scoring within the HubSpot ecosystem by transitioning from native, rigid manual rules to a highly decoupled, webhook-driven, API-integrated custom architecture provides unparalleled precision and scalability in revenue operations. By routing complex CRM telemetry through Operations Hub workflow webhooks, crucial behavioral and demographic data is liberated from the limitations of the native ecosystem. This architectural paradigm allows for the seamless integration of third-party platform telemetry, the execution of exponential decay functions, and the deployment of AI-driven probabilistic modeling to evaluate prospect viability.
Achieving enterprise-grade reliability in this decoupled system demands rigorous adherence to cryptographic security protocols, specifically executing v3 signature validation to prevent payload spoofing and replay attacks. It requires the deployment of asynchronous message queues to bypass HubSpot’s strict 5-second webhook delivery timeouts, coupled with bulletproof composite-key idempotency to mitigate duplicate event corruption caused by aggressive network retries. Ultimately, by marrying high-performance queue consumption with batched CRM API updates and proactive rate limit throttling algorithms, organizations can construct a highly scalable, fault-tolerant lead scoring engine. This ensures that marketing and sales teams engage exclusively with computationally verified, high-velocity prospects, driving profound efficiencies across the revenue lifecycle.


